ABAQUS#
Versions Installed
Kay: 6.14-6 / 2017 / 2018 / 2019
LXP: 2023
Description#
The ABAQUS suite of software for finite element analysis (FEA) is known for its high performance, quality and ability to solve more kinds of challenging simulations than any other software. The ABAQUS suite consists of three core products - ABAQUS/Standard, ABAQUS/Explicit and ABAQUS/CAE. Each of these packages offers additional optional modules that address specialized capabilities some customers may need.
ABAQUS/Standard®, provides ABAQUS analysis technology to solve traditional implicit finite element analyses, such as static, dynamics, thermal, all powered with the widest range of contact and nonlinear material options. ABAQUS/Standard also has optional add-on and interface products with address design sensitivity analysis, offshore engineering, and integration with third party software, e.g., plastic injection molding analysis.
ABAQUS/Explicit®, provides ABAQUS analysis technology focused on transient dynamics and quasi-static analyses using an explicit approach appropriate in many applications such as drop test, crushing and many manufacturing processes.
ABAQUS/CAE®, provides a complete modeling and visualization environment for ABAQUS analysis products. With direct access to CAD models, advanced meshing and visualization, and with an exclusive view towards ABAQUS analysis products, ABAQUS/CAE is the modeling environment of choice for many ABAQUS users.
License#
Our license specifically permits us to enable use of the software only by researchers from the academic institutions listed below :
NUIG
UL
TCD
UCC
UCD
RCSI
Munster Institute of Technology
If you are from one these institutions, contact Helpdesk to add your username to the UNIX group “abaqus” thus allowing you to access this package.
Our license includes 504 tokens on Kay, where tokens are consumed at the rate of int(5 x N0.422) tokens per instance, where N is the number of CPUs for each job. The license token consumption as a function of processor cores for a job is plotted below:
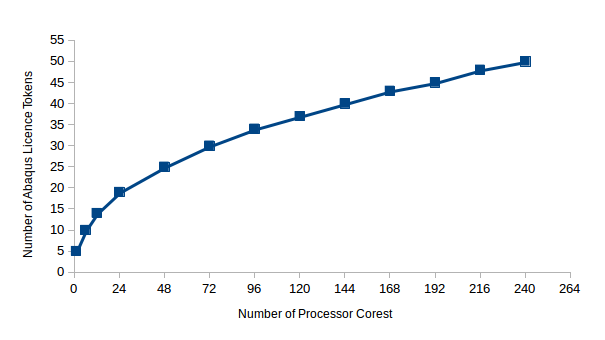
Benchmarks#
Information here is used for benchmarking the Abaqus 6.13-2. There are two main types of benchmarks suggested by SIMULIA which is for the two of its core products. They are Standard Server Benchmarks and Explicit Server Benchmarks for ABAQUS/Standard® and ABAQUS/Explicit® respectively. Please look here to compare the performance of Abaqus on various different hardware platforms.
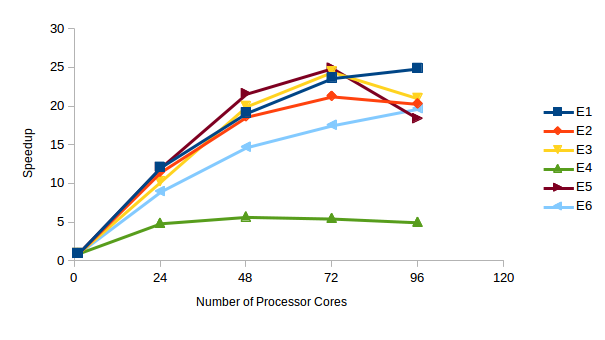
Standard Server Benchmark
Benchmark Execution Time in Seconds (Speedup)
Cores(Tokens) |
E1 |
E2 |
E3 |
E4 |
E5 |
E6 |
|---|---|---|---|---|---|---|
1 |
114658 |
(1)7098 |
(1)6927 |
(1)573 |
(1)1972 |
(1)6943 (1) |
24 |
241207 |
(12.14)616 |
(11.52)673 |
(10.29)117 |
(4.9)163 |
(12.1)771 (9.01) |
48 |
48765 |
(19.16)380 |
(18.68)346 |
(20.02)100 |
(5.73)91 |
(21.67)471 (14.74) |
72 |
72619 |
(23.68)333 |
(21.32)283 |
(24.48)104 |
(5.51)79 |
(24.96)395 (17.58) |
96 |
96588 |
(24.93)349 |
(20.34)329 |
(21.05)114 |
(5.03)107 |
(18.43)352 (19.72) |
This benchmark is focused on the ‘ABAQUS Standard’ part of the product. From the above figure it can be seen that the amount of achieved speedup starts reducing after scaling across multiple nodes. In case of the S2A benchmark there was drop in the performance observed while scaling from three to four nodes.
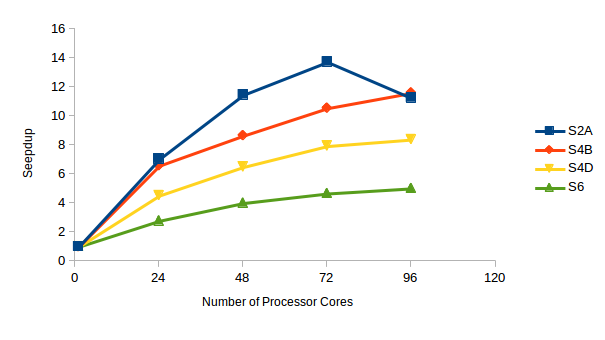
Explicit Server Benchmark
Benchmark Execution Time in Seconds (Speedup)
Cores(Tokens) |
S2A |
S4B |
S4D |
S6 |
|---|---|---|---|---|
1 |
11182 |
(1)3378 |
(1)3114 |
(1)4375 (1) |
24 |
24168 |
(7.04)513 |
(6.58)688 |
(4.53)1571 (2.78) |
48 |
48103 |
(11.48)390 |
(8.66)479 |
(6.5)1091 (4.01) |
72 |
7286 |
(13.74)320 |
(10.56)392 |
(7.94)937 (4.67) |
96 |
96105 |
(11.26)291 |
(11.61)371 |
(8.39)871 (5.02) |
This benchmark is focused on the ‘ABAQUS Explicit’ part of the product. The figure above shows that the E4 benchmark did not scale across nodes while for the E5 benchmarks, the amount of achieved speedup was reduced on scaling from three to four nodes. In overall comparison it could be said that the ABAQUS Explicit benchmarks showed good speedup when scaled across three nodes i.e. 72 cores. Little is gained beyond three nodes.
Job Submission Example#
Abaqus is installed under /ichec/packages/abaqus and is accessible via environment modules. On Kay the most recent being the default version is:
module load abaqus/6.14-6
or
module load abaqus/2018
On Meluxina we have 2023 installed.
module load abaqus/2023
Abaqus jobs must be submitted using the Slurm queueing system. The following is an example Slurm script for running an Abaqus job on 40 cores of the Kay system for a maximum runtime of 30 hours:
Script for kay#
#!/bin/bash -l
#SBATCH -J MyJobName
#SBATCH -A myaccount
#SBATCH --nodes=1
#SBATCH --time=30:00:00
#SBATCH -p ProdQ
#
#SBATCH --ntasks-per-node=40
#SBATCH --cpus-per-task=1
#SBATCH -o %x-%j.log
### Load ABAQUS module
module load abaqus/6.14-6
### Configure environment variables, need to unset SLURM's Global Task ID for ABAQUS's PlatformMPI to work
unset SLURM_GTIDS
### Create ABAQUS environment file for current job, you can set/add your own options (Python syntax)
env_file=abaqus_v6.env
cat << EOF > ${env_file}
#verbose = 3
#ask_delete = OFF
# Location of scratch directory
## multi-node jobs should use the scratch on Lustre
scratch="/scratch/global"
## single-node jobs can use the scratch on the node for better performance (max 400GB)
# scratch="/scratch/local"
mp_mpirun_options="-TCP"
EOF
node_list=$(scontrol show hostname ${SLURM_NODELIST} | sort -u)
mp_host_list="["
for host in ${node_list}; do
mp_host_list="${mp_host_list}['$host', ${SLURM_CPUS_ON_NODE}],"
done
mp_host_list=$(echo ${mp_host_list} | sed -e "s/,$/]/")
echo "mp_host_list=${mp_host_list}" >> ${env_file}
### Set input file and job (file prefix) name here
job_name=${SLURM_JOB_NAME}
### ABAQUS parallel execution
input_file=input.inp
abaqus job=${job_name} input=${input_file} double=both cpus=${SLURM_NTASKS} mp_mode=mpi interactive
Script for Meluxina#
#!/bin/bash -l
#SBATCH -J MyJobName
#SBATCH -A myaccount
#SBATCH --nodes=1
#SBATCH --time=30:00:00
#SBATCH -p cpu
#SBATCH --qos default
# disable multithreading. Please check both cases to see which gives better performance
#SBATCH --hint=nomultithread
#SBATCH --ntasks-per-node=128
#SBATCH --cpus-per-task=1
#SBATCH -o %x-%j.log
### Load ABAQUS module
module load abaqus/2023
### Configure environment variables, need to unset SLURM's Global Task ID for ABAQUS's PlatformMPI to work
unset SLURM_GTIDS
### Create ABAQUS environment file for current job, you can set/add your own options (Python syntax)
env_file=abaqus_v6.env
cat << EOF > ${env_file}
#verbose = 3
#ask_delete = OFF
# Location of scratch directory
## multi-node jobs should use the scratch on Lustre
scratch="/scratch/global"
## single-node jobs can use the scratch on the node for better performance (max 400GB)
# scratch="/scratch/local"
mp_mpirun_options="-TCP"
EOF
node_list=$(scontrol show hostname ${SLURM_NODELIST} | sort -u)
mp_host_list="["
for host in ${node_list}; do
mp_host_list="${mp_host_list}['$host', ${SLURM_CPUS_ON_NODE}],"
done
mp_host_list=$(echo ${mp_host_list} | sed -e "s/,$/]/")
echo "mp_host_list=${mp_host_list}" >> ${env_file}
### Set input file and job (file prefix) name here
job_name=${SLURM_JOB_NAME}
### ABAQUS parallel execution
input_file=input.inp
abaqus job=${job_name} input=${input_file} double=both cpus=${SLURM_NTASKS} mp_mode=mpi interactive
Assuming that this Slurm script is saved as abaqus.sh, the job can be
submitted to the queue by running the following command in the same
directory:
sbatch abaqus.sh
User Defined Functions#
Compilation#
To compile user defined functions using the Intel Compilers on Kay as appropriate modules need to be loaded. Please add below lines in your Slurm script to make Intel Compilers available.
module load intel/2018u4
Note
Most subroutines contained within Abaqus are thread-safe, meaning they can be called during a parallel Abaqus simulation without the risk of producing unwarranted results. If a user defined function or elelement is being used in parallel, it does not need to contain explicit MPI function calls but it does need to be thread-safe. Meaning that data is not unknowingly overwritten by different processes.
Restarting an interrupted Abaqus analysis#
It is sometimes necessary to restart an Abaqus analysis on ICHEC systems if, for example, the analysis being run requires a greater walltime than allowed by the queueing policy on the system. There is no single procedure for restarting an Abaqus analysis because the restart procedure typically depends on the type of analysis being conducted. The procedure described in this section is only for continuing a system-interrupted analysis.
To continue an interrupted analysis, the analysis to be continued, myJob in this example, should have been configured to write restart files at a specified frequency before being run. This can be configured in Abaqus/CAE under Output -> Restart Requests in the Step module. After the analysis myJob has been interrupted by the system, it may be continued as follows:
Abaqus/Standard#
To continue an interrupted Abaqus/Standard analysis, a new analysis (myJob_restart for example) should be created in which the only steps defined are those subsequent to the step from which the analysis is being continued. In addition, the new analysis should be configured to read restart data from the previous analysis. In Abaqus/CAE, this can be configured by selecting Model->Edit Attributes->->Restart->Read data from job in any module.
The job can then be submitted using a Slurm script as described in the previous section, in which the analysis to be restarted is specified by supplying the oldjob= option to the abaqus command in the Slurm script, e.g.:
abaqus job=myJob_restart inp=myJob_restart.inp oldjob=myJob cpus=40 interactive
On Meluxina, you should change the cpu option as cups=128 or cpus=256 depending on whether you have hyperthreading enabled or not.
Abaqus/Explicit#
To continue an Abaqus/Explicit analysis, a new analysis does not need to be created. Instead, the analysis can be restarted by supplying the recover option to the abaqus command in the Slurmscript, e.g.:
abaqus job=myJob inp=myJob.inp recover cpus=40 interactive
Checking License Availability in Slurm#
On Kay, users are required the number of tokens required per job so that jobs will only be started if there are enough tokens available. This can be done by including the following lines in the Slurm script. Note that this is only effective if you correctly calculate and specify your token requirements.
#SBATCH -L abaqus:M
Where for N cores, \(M = \textsf{int}(5\times N^{0.422})\), giving \(M = 23\) tokens for 40 cores, 31 for 80 cores, 37 for 120 cores and 42 for 160 cores. For a 40 core job:
#SBATCH -L abaqus:23
Further information can be found here.