
2. Quantum machine learning for Earth observation#
Topic 2: QSVM4EO#
This notebook will present the an example of using quantum-enhanced support vector machines (QSVM) for classification tasks on multi-spectral Earth Observation (EO) data. The main topics covered are introduction to classical SVM, where quantum computation could be used in the SVM calculations, the intricacies of preparing and encoding the classical data into useful quantum states and training QSVMs on gate-based quantum software simulators. Finally, some results on comparing classical and quantum-enhanced SVM models will be presented.
QSVM code is adapted from Qiskit QSVM example:
https://qiskit-community.github.io/qiskit-machine-learning/tutorials/03_quantum_kernel.html
Introduction#
Use case#
The proliferation of EO data from diverse sources in recent years has exhibited an exponential growth in both the volume and quality of data. This exponential growth requires new approaches to managing and using the data, taking advantage of advancements in contemporary technologies. Machine Learning (ML) techniques offer promising venues for investigating new ways of gaining insight from the data. Combined with new computing paradigms, like Quantum Computing (QC), this approach is a promising aspect to achieve results faster and, potentially, with higher accuracy. Quantum Machine Learning, a fusion of classical ML and quantum mechanics, leverages entanglement and superposition to uncover hidden data patterns, potentially reducing computational resources and processing time.
Goals:
Keep exploring and adding examples to the state of the art of QC4EO
Investigate setting up HPC-QC pipelines for EO data
Look for use cases where QML could potentially provide advantage over classical ML
Evaluate performance of QSVM on “high” amount of data (starting with basic quantum encoding schemes)
Offloading of processing on satellites once Quantum Computers are available onboard
Theory#
Classical Machine Learning and Quantum Machine Learning#
Combining quantum computing with machine learning leads to a new and intriguing discipline - quantum machine learning (QML). As we could also have classical or quantum data, we end up with four different combinations, depending of the type of the computation and the type of data used:
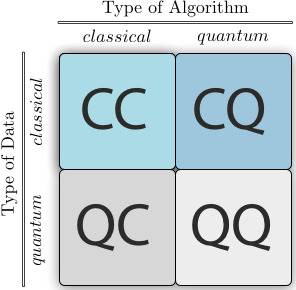
Fig. 1 Source: Schuld, M. and Petruccione, F. (2021), Machine Learning with Quantum Computers, Springer.#
The typical flow in training and performing inference with a QML algorithm is similar to classical ML, with two extra steps. Since we’re dealing with classical data, it needs to be converted into quantum data. This is done in the Input encoding step (also called state preparation) and it’s not a trivial step and has great repercussions on the performance of the model. Once the processing is done on the quantum computer, to get access to the result a Read out or measurement step needs to be performed, as the information in the qubits is not directly accessible.
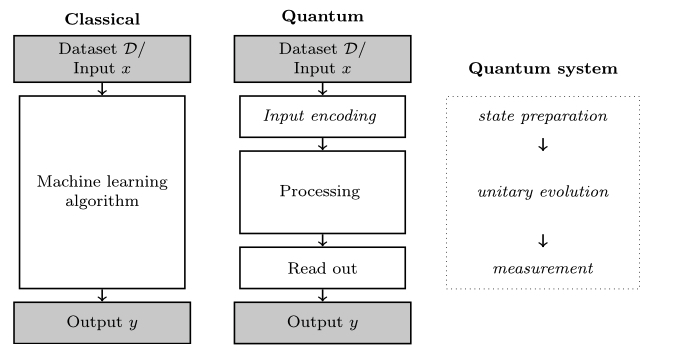
Fig. 2 Source: Schuld, M. and Petruccione, F. (2021), Machine Learning with Quantum Computers, Springer.#
Classical data needs to be converted to quantum states before it could be manipulated by quantum computers. There are different quantum encoding(sometimes also called also quantum embedding or quantum feature map) techniques, all with the common goal of translating a classical datapoint \(x\) into the state of qubits or parameters of quantum gates with the final goal of creating an initial quantum state \(\mid\psi\rangle\), dependent on the initial datapoint. Three popular basic quantum encoding are basis encoding, amplitude encoding and rotation encoding. The rotation encoding` applies a parametrized rotation gate to a qubit (for example Pauli Z rotation) for each classical data feature.
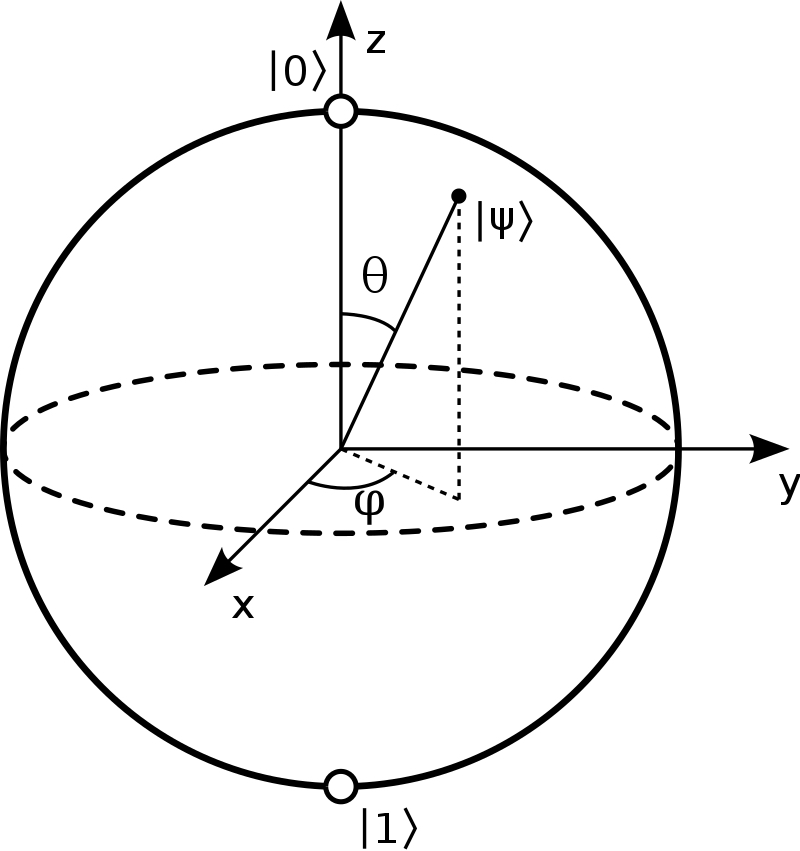
Fig. 3 A qubit, visualized as a point on a sphere.#
Support Vector Machines (SVM)#
The SVM algorithm, in it’s original linear definition, is very similar to the linear classifier. But instead of trying to find any hyperplane separating the two data classes, it’s goal is to find the maximum margin between them with the assumption that they are linearly separable.
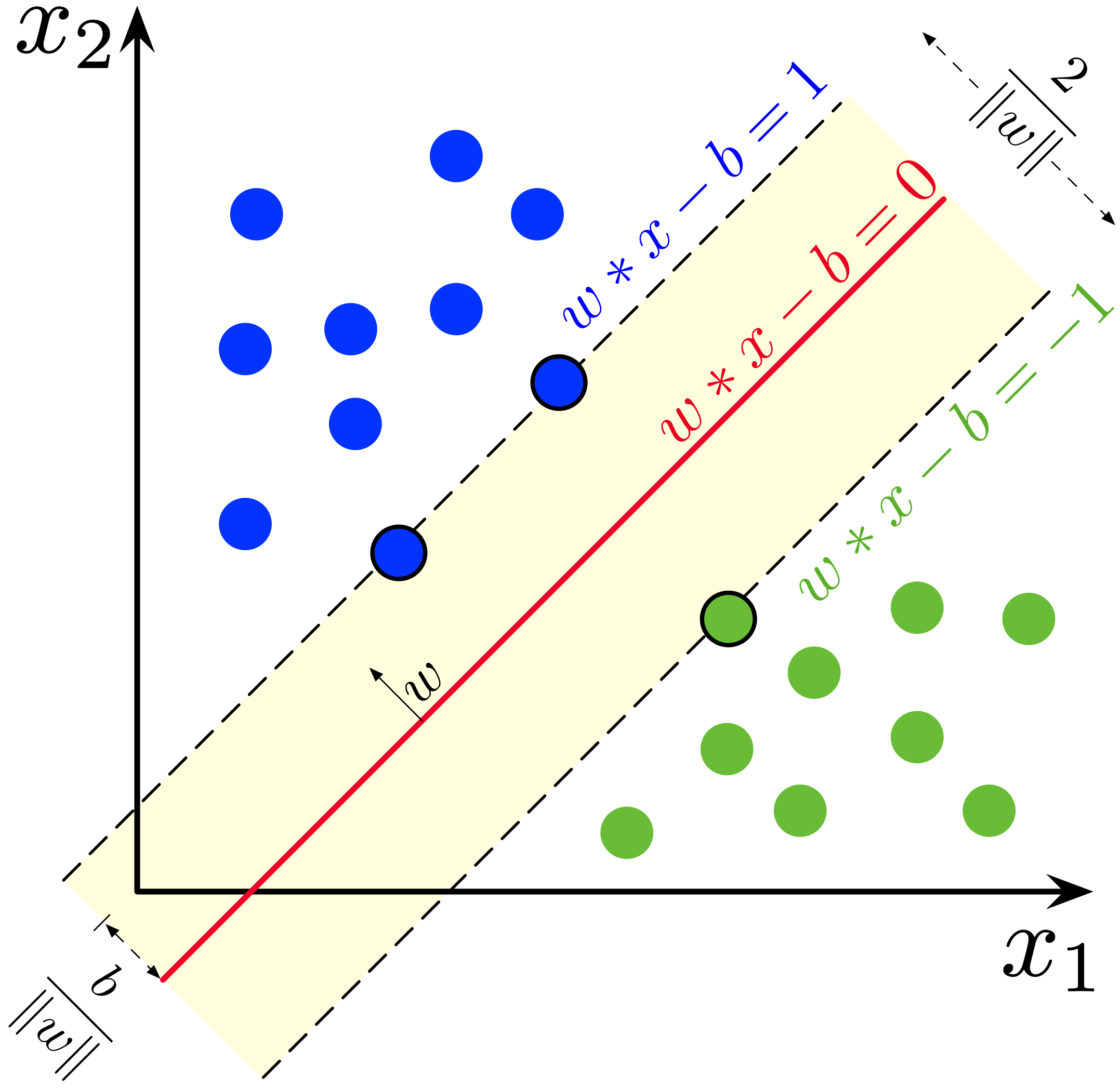
Fig. 4 Source: Source: Wikipedia#
{kind=link}
Primal formulation#
The separation line is computed by the following equation:
This could be reformulated as an optimization problem:
with the following constraints:
Dual Lagrangian formulation#
In practice the Dual Lagrangian formulation is used:
Lagrangian
which is maximized w.r.t. to \(\alpha\) subject to constraints:
In this formulation the values of the Lagrangian multipliers \(\alpha\) could be found with quadratic programming.
Kernel trick#
The above formulations work for linearly separable data, but the real-world datasets are rarely linearly separable. In cases where the data points are intermixed, one could use a transformation function that is applied to the original datapoints \(x_i\) that maps them to a new feature space. The hope is that in this new feature space the mapped datapoints \(z_i\) are linearly separable.
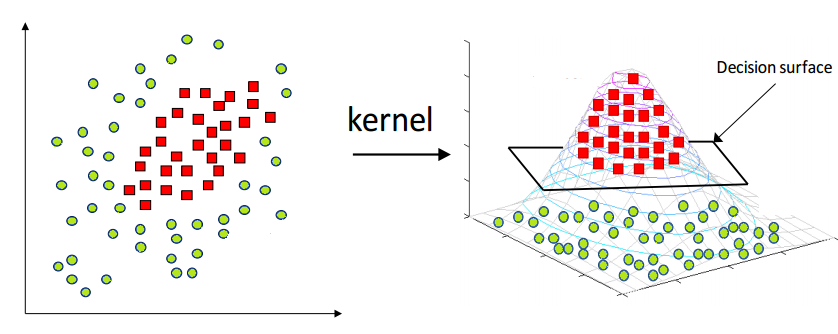
Fig. 5 Source: https://www.hackerearth.com/blog/developers/simple-tutorial-svm-parameter-tuning-python-r/#
subject to:
Computing those new datapoints \(z_i\) could be quite computationally expensive. To avoid it we could apply the kernel trick: instead of computing each new datapoint in the new feature space, what we need is some measure of distance between the datapoint vectors, for example their dot product, as seen in the equation above. So if we could compute it directly, by using the data in the original input space, we could speed up the computation and get access to kernels in infinite dimensions (for example the RBF kernel).
Some classical kernel functions:
Name |
Kernel |
Hyperparameters |
|---|---|---|
Linear |
\(\mathbf{x}^{T} \mathbf{x}^{\prime}\) |
- |
Polynomial |
\(\left(\mathbf{x}^{T} \mathbf{x}^{\prime}+c\right)^{p}\) |
\(p \in \mathbb{N}, c \in \mathbb{R}\) |
Gaussian |
\(\mathrm{e}^{-\gamma\left|\mathbf{x}-\mathbf{x}^{\prime}\right|^{2}}\) |
\(\gamma \in \mathbb{R}^{+}\) |
Exponential |
\(\mathrm{e}^{-\gamma\left|\mathbf{x}-\mathbf{x}^{\prime}\right|}\) |
\(\gamma \in \mathbb{R}^{+}\) |
Sigmoid |
\(\tanh \left(\mathbf{x}^{T} \mathbf{x}^{\prime}+c\right)\) |
\(c \in \mathbb{R}\) |
Quantum-enhanced Support Vector Machines (QSVM)#
Quantum Dot product#
A single qubit state is mathematically defined as a unit vector in a two-dimensional complex vector space, i.e. a Hilbert Space. We could write the qubit state would be by using the vector notation - this is called a ket :
As the coefficients (or amplitudes) \(\alpha\) and \(\beta\) are complex number, we can take their conjugates \(\bar{\alpha}\) and \(\bar{\beta}\):
The conjugates helps us introduce the complement of a ket, called a bra, which is it’s conjugate transpose:
With this notation it becomes very easy to write dot products of quantum states in Hilbert space - for example the dot product of the state \(\mid \psi\rangle\) with itself is defined as follows:
Quantum Kernels#
Constructing quantum kernels is surprisingly simple. One approach is to first encode feature \(x_n\) using rotation encoding routine \(S(x_n)\). This produces a quantum state \(\mid \phi\rangle\), parametrized on \(x_n\). Then we reuse the same quantum circuit and this time encode feature \(x_m\) using the inverse embedding \(S(x_m)^†\), which produces a quantum state \(\langle \phi\mid\), this time parametrized on \(x_m\). This now forms a circuit, which is the dot product of the two encoded states, which defines a distance measure in Hilbert space. The last step is to perform projective measurement on the initial state, which produces the following quantum embedding kernel (QEK), dependent only on the two original classic data features \(x_n\) and \(x_m\):
By encoding the data into quantum Hilbert Space in a clever way and without doing any additional operations we’re able to get a kernel producing a distance measure between datapoints.
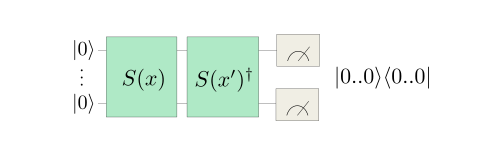
Fig. 6 Source: Pennylane tutorial#
Now we could put everything together and define a quantum-enhanced version of Quantum Support Vector Machines (QSVM). In this particular version of QSVM all the classical computation steps in training a model and performing inference stay the same, with the exception of the computation of the kernel matrix, which is performed on a quantum computer or quantum software simulator. The dual Lagrangian is modified as follows:
Lagrangian, Quantum
where \(\phi(x_i)\) is a quantum feature map, encoding the classical data vector \(x_i\) into quantum Hilbert space.
Comparison of the steps of a classical and quantum-enhanced SVM is shown below:
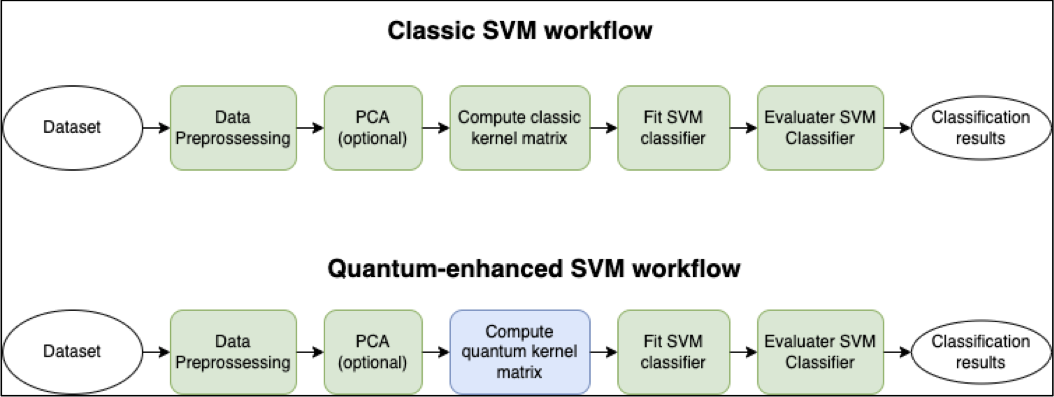
Fig. 7 Classical and Quantum enhanced SVG workflow#
Dataset#
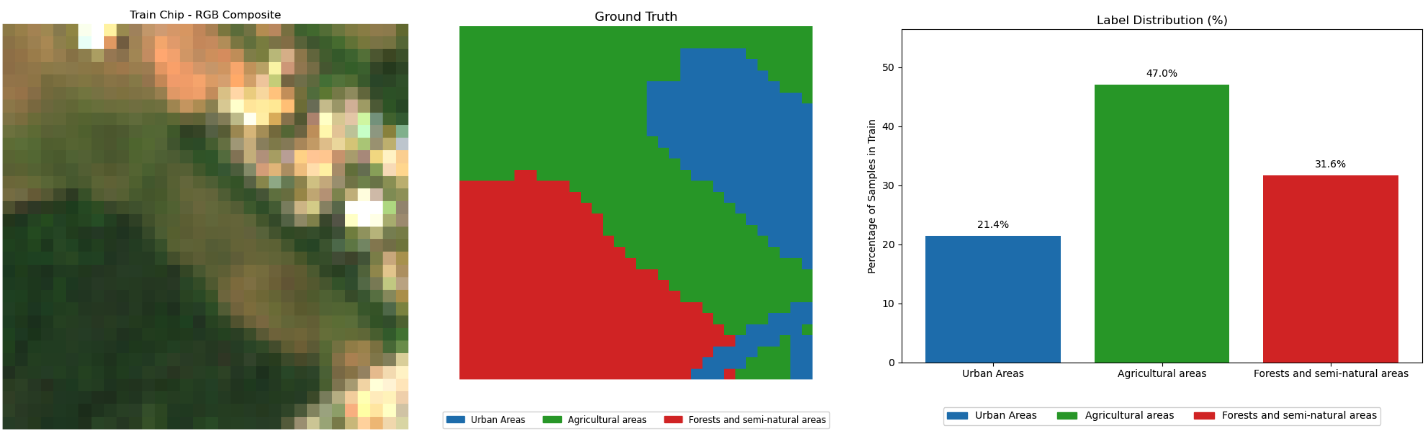
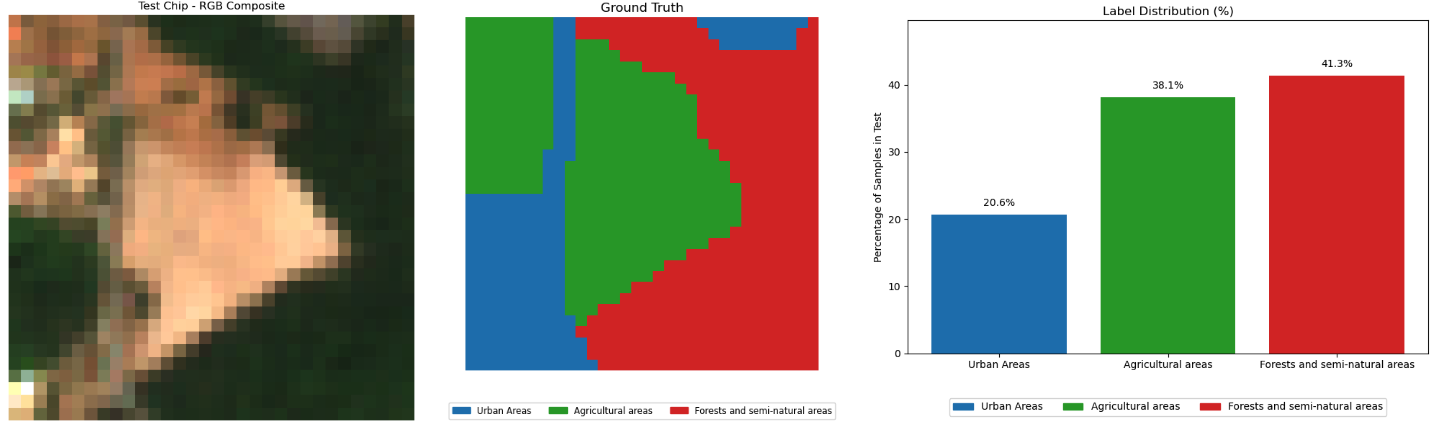
Dataset source: MultiSen – France, South-West – https://zenodo.org/records/6375466
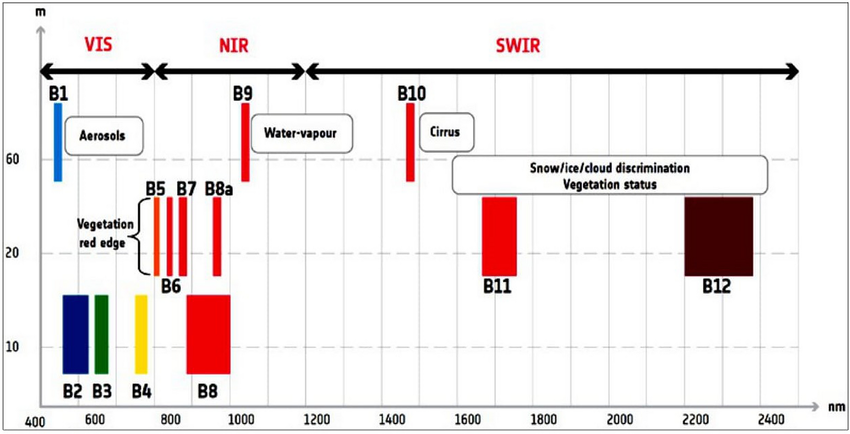
Sentinel-2 multi-spectral data with labels:
Bands 02, 03, 04 and 08 values for each of the selected pixels was extracted
NDVI, EVI, SAVI and NDWI indices were calculated and added
Tiles: Two rural regions with size \(32\times 32\) in south-western France selected. Each tile contains pixels in one of the follow 3 categories:
Urban areas
Agricultural areas
Forests and semi-natural areas
Train tile:#
Test tile:#
Tutorial notebook
The tutorial notebook is in folder exercise2 of the QTrain repository.
Notebook link: ICHEC/QTrain
Conclusions and future work#
Conclusions:
QSVM shows promising potential in the EO use case
Some quantum encoding schemes perform on par with the best classical SVM kernels
Future work:
Investigate other quantum encoding schemes
Investigate other quantum computing modalities – ie analog quantum computing
Investigate other quantum machine learning techniques – ie quantum reservoir computing
Run on actual quantum hardware
References#
https://qiskit-community.github.io/qiskit-machine-learning/tutorials/03_quantum_kernel.html
https://docs.quantum.ibm.com/api/qiskit/qiskit.circuit.library.ZFeatureMap
https://docs.quantum.ibm.com/api/qiskit/qiskit.circuit.library.ZZFeatureMap
https://pennylane.ai/qml/demos/tutorial_kernel_based_training
Acknowledgements#
We extend our gratitude to the Irish Centre for High-End Computing (ICHEC) and University of Galway for providing computing and for all-encompassing invaluable support. This project was funded by the EuroHPC JU under grant agreement No 951732 and Ireland.
